别再只跟 AI 聊天了——用工程思维驯服你的 OpenClaw
一、花三万块聊天调教 AI,值吗?
3 月 4 日,公司组织大家看了傅盛的“14天卧床训了只龙虾三万”的直播。他展示了自己如何通过聊天工具,跟 OpenClaw 的”龙虾”三万聊了几千条消息,不断教它规则、改规则、加功能。光 API 调用费就花了三万多。
看完之后,我一直在想一个问题:
如何让龙虾的记忆和技能是确定的东西,而不是一句话一句话的调教。
对话式调教的问题很明显:
- 这种调教可能带来龙虾的信息冗余,因为龙虾自己不断在之前的规则上反复修改。
这不是说傅盛的方法不好。对于快速试错、探索边界,聊天是最快的方式。但如果你要的不是一次惊艳的演示,而是一只能可靠干活、能持续迭代、能交给团队使用的龙虾——
你需要的不是更多对话,而是一份工程规格书。
它叫 SKILL.md。
二、为什么工程师应该关心这件事
过去一年,我们跟很多高校老师和企业客户讨论过同一个问题:怎么把 AI 融入到无人机和机器人的课程中?
讨论到最后,总会撞上同一堵墙:
AI 的不可预知性和黑盒效应,导致从工程师思维来说,它不能 100% 可靠地拿来教学和使用。
这句话说到了点子上。工程师要的是确定性。你告诉飞控”悬停在 2 米”,它就悬停在 2 米,误差可控。但你告诉 AI”讲解 PID 控制”,它今天讲得好,明天可能跑偏。
怎么解决?
答案藏在 OpenClaw 的 Skill 机制里。Skill 的本质,是用工程化的方式,把 AI 的行为从”不可预知”变成”基本可控”。
但前提是——你得读懂它的规格说明。
三、官方已经告诉你怎么写了——只是你可能没看
很多人不知道,OpenClaw 官方工程里自带了一个叫 skill-creator 的 Skill。没错,OpenClaw 用一个 Skill 来教你怎么写 Skill。
这份 373 行的官方规格文档,开篇第一句核心原则就是:
“Default assumption: Codex is already very smart. Only add context Codex doesn’t already have.”
默认假设:AI 已经很聪明了。只添加它还不知道的上下文。
这句话值得每个想写 Skill 的人反复读三遍。它直接否定了”把你知道的全都塞进去”这种本能冲动。
skill-creator 还明确规定了哪些东西不要放进 Skill:
“Do NOT create extraneous documentation or auxiliary files, including: README.md, INSTALLATION_GUIDE.md, QUICK_REFERENCE.md, CHANGELOG.md… The skill should only contain the information needed for an AI agent to do the job at hand.”
翻译成人话就是:Skill 是给 AI 看的工作指令,不是给人看的产品文档。 学员推荐语、公司介绍、安装指南——这些是给人看的,AI 不需要。
建议每个想认真写 Skill 的人,都去读一遍这个官方文档。它就在 OpenClaw 的 skills/skill-creator/SKILL.md 路径下。
接下来,我把其中最关键的规则拆解给你。
四、Skill 不是提示词,是工程交付物
很多人把 Skill 理解成”高级提示词”——把对话中说的那些话,整理成一个文件而已。
不是。
Skill 的本质是一份机器可读的入职指南。它把一个通用 AI 变成你的领域专家。就像你给新同事写的工作手册:不需要写”你要认真工作”(废话),而是写”审批超过 5 万的合同要抄送法务”(AI 不知道的、你组织独有的知识)。
官方定义的 Skill 工程结构:
my-skill/
├── SKILL.md ← 唯一必需文件:指令主体
├── references/ ← 按需加载的参考资料
│ ├── api-docs.md
│ └── domain-knowledge.md
├── scripts/ ← 确定性工具脚本
│ └── validate.py
└── assets/ ← 输出时使用的模板/素材核心只有 SKILL.md。其他全是按需加载——AI 需要时才去读,不浪费一个 token。
这个结构和你写一个 ROS 功能包没有本质区别:有主文件、有配置、有依赖、有工具脚本。如果你能写 CMakeLists.txt,你就能写 SKILL.md。而且写 SKILL.md 比写 CMake 简单得多。
五、SKILL.md 的规格说明
5.1 头部:决定龙虾什么时候醒来
---
name: my-skill
description: "做什么 + 什么时候用。当用户需要:(1) 场景一,(2) 场景二,(3) 场景三时使用。"
metadata:
{ "openclaw": { "emoji": "🔧" } }
---三个字段,三个硬性要求:
| 字段 | 要求 | 常见错误 |
|---|---|---|
name |
小写+连字符,≤64 字符,必须与文件夹同名 | 用中文、用空格、名称和目录不一致 |
description |
同时包含做什么和什么时候触发 | 只写”这是一个XX工具”,没有触发条件 |
metadata |
OpenClaw 专属配置(emoji、依赖等) | 忘写,导致平台功能缺失 |
description 是整个 Skill 最重要的字段。 它是 AI 判断”要不要激活这个 Skill”的唯一依据。写得模糊,龙虾就不知道什么时候该醒来。
好的 description:
“无人机 PX4 飞控开发培训。当用户需要:(1) 学习 PX4 开发,(2) 搭建仿真环境,(3) 调试飞控算法时使用。”
差的 description:
“帮助用户学习无人机。”
前者触发精准。后者太模糊,几乎什么对话都能匹配。
5.2 正文:只写 AI 不知道的
正文的核心原则只有一个:
AI 已经很聪明了。只写它不知道的。
这一条原则可以砍掉你 50% 的内容。
你不需要告诉 AI 什么是 PID 控制——它知道。你不需要告诉 AI rostopic 怎么用——它知道。你需要告诉它的是:
- 你的项目用哪个版本的 PX4(它不知道)
- 遇到 Offboard 问题应该先读哪份文档(它不知道)
- 你的组织用什么样的学习闭环方法论(它不知道)
正文结构的推荐模板:
# Skill 名称
## 何时使用
✅ 使用场景列表
## 何时不使用
❌ 边界定义 → 用什么替代
## 核心指令
[AI 执行任务的具体步骤和规则]
## 参考文档索引
[关键词 → 应该读哪个文件]“何时不使用” 和”何时使用”一样重要。它划定边界,防止龙虾在不该出手的时候强行套用。比如你的无人机 Skill 不适用于固定翼,就要明确写出来——否则有人问固定翼的问题,它也会硬着头皮回答,而且可能答错。
5.3 参考资料:渐进式披露
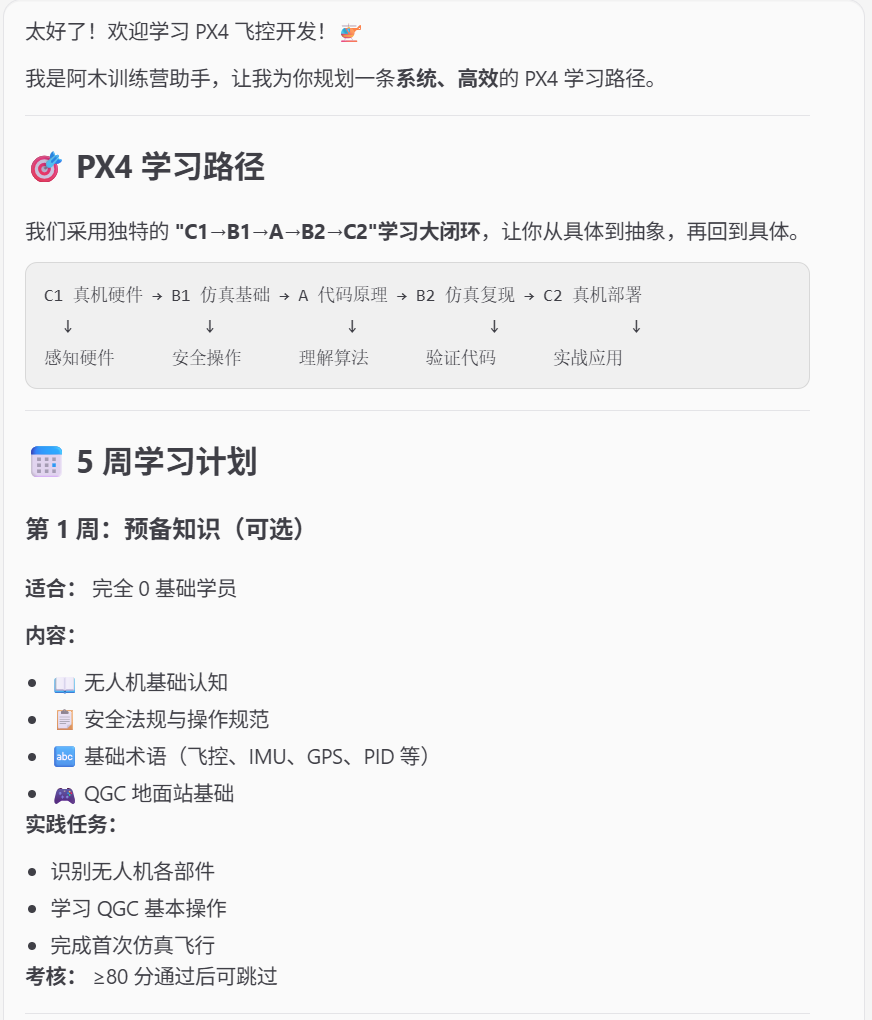
OpenClaw 有一个精妙的三级加载机制:
第一级:description(~100 词) → 始终在上下文中,用于触发匹配
第二级:SKILL.md 正文(<500 行) → Skill 激活后加载
第三级:references/(无限制) → AI 按需读取这意味着 SKILL.md 应该是索引,而不是百科全书。
错误做法:在 SKILL.md 里写 2000 行的 PX4 API 文档。
正确做法:在 SKILL.md 里写”PX4 架构详情见 references/px4-architecture.md“。
500 行,是 SKILL.md 的硬上限。 超了就该拆到 references/ 目录里。
六、冗余检测:怎么判断你的龙虾胖不胖
写完 SKILL.md 之后,对着每一行问自己三个问题:
检测 1:AI 本来就知道吗?
如果你写了:
“ROS 使用话题(Topic)进行发布-订阅通信。”
删掉。AI 知道。这是在浪费 token 教 AI 它已经会的东西。
如果你写了:
“本项目使用 PX4 v1.14.3,payload_deliverer 模块是核心学习案例。”
保留。这是你的项目独有的信息,AI 无从得知。
检测 2:这条信息值它的 token 吗?
上下文窗口是公共资源。你的 Skill 和对话历史、其他 Skill、用户请求共享这个窗口。每多写一行,就挤占其他内容的空间。
问自己:如果我只能保留 100 行,这行会在里面吗?
检测 3:删掉它,AI 的表现会变差吗?
最实际的测试。把你怀疑多余的内容注释掉,跑几个真实任务。如果 AI 表现没有任何区别——恭喜,你找到了一条冗余信息。
一个真实案例
我们对自己的阿木训练营 Skill 做了一轮基于这套方法的优化:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| SKILL.md 行数 | 581 行 | 184 行 |
| 是否超 500 行限制 | 超了 81 行 | 远低于限制 |
| 引用了但不存在的文件 | 14 个 | 0 个 |
| name 与目录名一致 | 不一致 | 一致 |
砍掉了什么? 学员推荐语、公司联系方式、PPT 页数、AI 本身就知道的安全检查清单、重复的流程图。没有一条影响 AI 的教学能力。这些是给人看的营销内容,不是给龙虾看的工作指令。
保留了什么? C1→B1→A→B2→C2 学习闭环方法论、PX4 标准源码、关键词到参考文档的路由表。每一条都是 AI 不知道的、阿木独有的知识。
比如 C1→B1→A→B2→C2 学习闭环——这是阿木训练营经过 2 年、跨越深圳、上海、西安、重庆多地培训后迭代出来的方法论。AI 绝对不可能自己推导出来,但它恰恰是整个教学 Skill 的灵魂:
C1 真机硬件拆解 → B1 仿真操作学习 → A 代码原理深入 → B2 仿真复现验证 → C2 真机部署
具体 验证 抽象 验证 具体先让学员拆真机,建立具象认知;再进仿真环境安全练手;然后深入代码理解抽象原理;接着回到仿真复现问题、验证修复方案;最后部署到真机完成闭环。从具体到抽象,再从抽象回到具体。
传统无人机教学要么纯理论(学完不会飞),要么直接上手(一来就炸机)。这套方法论解决的正是这个痛点——而这种经过实践验证的流程知识,正是 Skill 中最有价值的部分。你写进 SKILL.md 的每一行,应该都是这个级别的信息。
这就是区别:聊天调教是在教 AI 当演员,工程化 Skill 是在教 AI 当工程师。
七、工程师的黄金时代
回到最初的问题:怎么把 AI 融入到课程和实际工作中?
答案不是”跟 AI 聊得更好”。答案是把你的领域知识,用工程化的方式,写成 AI 能读懂的规格文件。
过去,让 AI 具备领域能力,需要训练模型、标注数据、调超参。那是机器学习工程师的活儿,门槛很高。
现在,你只需要写一个 Markdown 文件。
但这个 Markdown 文件的质量,取决于你对两件事的理解深度:
- 你的业务 —— 你知道哪些是领域独有的知识,哪些是通识
- 你的工程素养 —— 你知道怎么组织信息、控制冗余、设计渐进式结构
这两样东西,恰恰是懂程序、懂业务的工程师最擅长的。
不需要 Python 训练脚本。不需要 GPU 集群。不需要标注 10 万条数据。
一个 SKILL.md,一个 references/ 目录,一个清晰的 description。
你就把一个通用 AI,变成了你的领域专家。
这是懂程序和业务的工程师,最好的时代。
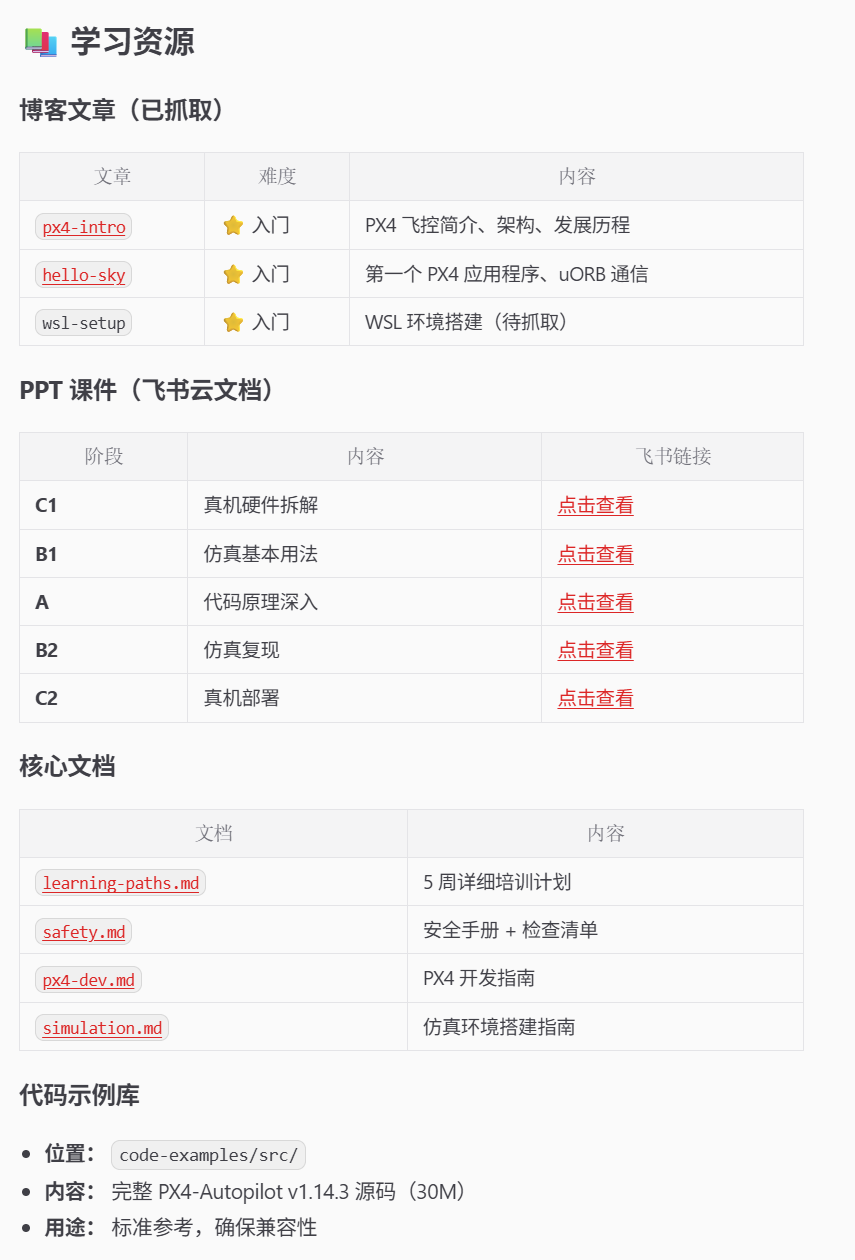
预告: 我们正在打磨阿木训练营的官方 Skill 包 amov-training——基于 PX4 飞控开发的全流程培训技能,内置 C1→B1→A→B2→C2 学习闭环、完整的课程资料索引,以及一个很多人会忽略但极其重要的东西:
我们把准确版本的 PX4 v1.14.3 源码,直接放进了 Skill 的 code-examples/ 目录里。
为什么要这么做?因为 PX4 不同版本之间差异巨大——API 接口变了、模块结构改了、参数定义调了、编译系统也换了。如果你跟着教程学,但本地装的是另一个版本,那就是对着菜谱炒菜但锅和食材全不对,怎么炒都不对味。

把标准源码打包进 Skill,意味着每一个使用这个 Skill 的学员,拿到的代码基线都是一致的。AI 在讲解 payload_deliverer 模块时,它读的就是 code-examples/src/ 里的真实代码,不是凭记忆生成的”大概长这样”的代码。
拿到这个 Skill 包之后,你可以直接导入到自己的 OpenClaw 龙虾或者 Cursor 中——把它变成你的 PX4 私人教练。问它 PX4应该怎么学、payload_deliverer 的代码逻辑是什么、仿真环境怎么搭,它都会基于我们提供的标准源码和课程体系来回答,而不是凭空编造。
它不是一份提示词。它是一套经过规范验证的、可复现的、导入即用的教学系统。
即将发布,敬请期待。
阿木实验室 · 让机器人研发更高效